
Over the years for 10's of projects that we've worked on, we have optimized our robots.txt and blocked many bots due to them stealing our data, affecting our website speed and server performance. In the month of August 2023, we decided to select 250 websites online from this source and look at their robots.txt to find out which bots they fully block.
We found that 40.80% (102 out of the 250) block one or more bots completely.
NOTE: All research, insights and opinions are made by One Scales and is for reference only. Make sure you always do your own research and consider your own specific needs and requirements.
REFERENCE: Not sure what is a robots.txt file, we made an article.
Our aim?
- To give you the awareness of bots and what they do.
- To give you a list of popular bots that you should consider blocking.
- [for geeky users] To give you the full data of all sites we looked at so that you can see for yourself.
What are Bots?
"Bots" refer to software or code designed to automate specific tasks to visit your website and read the content of your pages. Bots can serve various purposes, such as indexing web pages for search engines such as Google, gathering data for research such as OpenAI (ChatGPT) and for machine learning, monitoring website health, SEO tools, or even engaging in malicious activities like scraping content or exploiting vulnerabilities.
Types of Bots
- (Auto) Bots, Crawlers & Scrapers - they typically crawl around the web, usually learn or save your content (aka scrape) and visit either website by website plus page by page until they discover all sites and pages. (aka crawling around the web). Note that they can be for a specific site or sets of pages as well.
- Manual Bots & Scrapers - they typcially are made for one website and/or page(s)
- Good Bots - are bots that goals are providing values in the world. For example - google bot is a good bot because it helps index the worlds information and helps people find information better and quicker in their search engine. Another example is an SEO tool that gives you a report of your site health.
- Bad Bots - are bots that try to harm your business or steal your information and use it for their own gain without providing back value.
Bot Categories
- Search Engine Bots - crawling your website to understand what your site is about and rank you. (typically "good bots", "auto" and "manual")
- Website and SEO Tools - used to analyze your SEO or Site functionality. (typically "good bots", "auto" and "manual")
- Web Scrapers - crawl your data and use it on other sites and for research (could be "good" and "bad" bots, "auto" and "manual")
- Manual Crawlers & Scrapers - developer code to read your website and/or use your content. (could be "good" and "bad" bots, "manual")
- Malicious Bots - Crawling your site to find vulnerabilities, hack you, steal your information or break your site (for example - an attack) (always "bad" bots, "auto" and "manual")
Why Would You Want To Block Bots?
- They copy your data and use it without your permission for monetary or other benefits. (for example they sell your data)
- They cost you money by using or overloading your servers with more requests of your website.
- They slow down your website which make the user experience of your visitors worse.
- They compete with you on your SEO by copying your website content and duplicating on their own site.
- They are malicious and trying to harm your website or business. (for example - try to hack you or break your site)
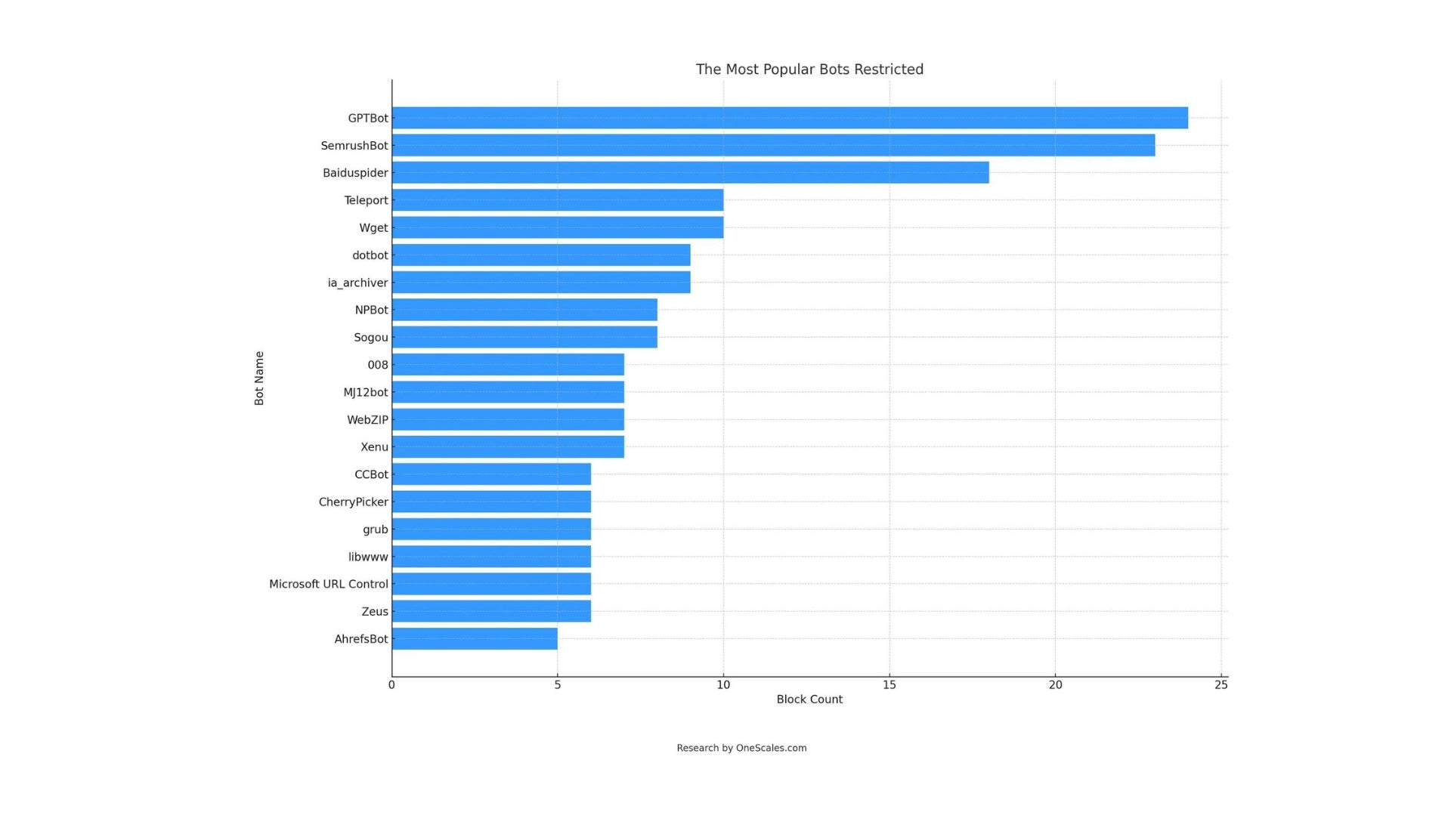
The Most Popular Bots Restricted
| Bot Name | Description |
|---|---|
| GPTBot |
OpenAI's ChatGPT Bot used to study the internet and make their AI knowledgable (used to improve future models and gain additional knowledge). URL: https://openai.com/blog/chatgpt Robots.txt Info: https://platform.openai.com/docs/gptbot
Note: If you don't want future training and learning from your content, you will want to block this bot. Note that from our study that some news sites and content creators decided to block them. |
| SemrushBot |
SEO analysis and website performance optimization from SEMRush online tool. URL: https://www.semrush.com/ Robots.txt Info: https://www.semrush.com/bot/
Note: If you're not using their tool, you may want to consider blocking them and unblock if you decide to use them. |
| Baiduspider |
Web crawler for Baidu search engine. (a Chinese search engine). URL: https://www.baidu.com/ Robots.txt Info: https://www.baidu.com/search/robots_english.html
Note: Probably don't want to block unless you don't want your site listed on Baidu. We've seen in our research that some cases sites blocked Baidu for the english version in order to have them only read their Chinese version of the site. |
| Teleport |
Web scraping and content extraction. URL: N/A (couldn't find an official link) Robots.txt Info: N/A (couldn't find an official link)
Note: High likelihood you want to block as we haven't seen any positive information about this bot online. |
| Wget |
Programmatic way for developers to get webpages and content via code. URL: https://www.gnu.org/software/wget/ Robots.txt Info: http://wget.addictivecode.org/FrequentlyAskedQuestions.html#robots
Note: Monitor your server logs and if you see traffic from it, you might want to block it assuming your developers are not using it. |
| dotbot |
Web crawler for Moz SEO Analysis. URL: https://moz.com/ Robots.txt Info: https://moz.com/help/moz-procedures/crawlers/dotbot
Note: If you're not using their tool, you may want to consider blocking them. If you decide to use them in the future, you unblock them. |
| ia_archiver |
Web crawler for Internet Archive which saves a copy of your webpages online over time from a reputable company. URL: https://archive.org/ Robots.txt Info: https://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/
Note: It's a great tool to see your website over time. Block only if you don't want them to store a copy of your website or if you have personal information that you don't want them to store. |
| NPBot |
General purpose web crawler. URL: N/A (couldn't find an official link) Robots.txt Info: N/A (couldn't find an official link)
High likelihood you want to block as we haven't seen any positive information about this bot online. |
| Sogou |
Web crawler for Sogou search engine. (a Chinese search engine). URL: https://www.sogou.com/ Robots.txt Info: https://help.sogou.com/spider.html
Note: Probably don't want to block unless you don't want your site information in this search engine. |
| 008 |
Web crawling service provider. URL: N/A (couldn't find an official link) Robots.txt Info: N/A (couldn't find an official link)
High likelihood you want to block as we haven't seen any positive information about this bot online. |
| MJ12bot |
Web crawler for Majestic SEO Tool. URL: https://majestic.com/ Robots.txt Info: https://www.mj12bot.com/
If you're not using their tool, you may want to consider blocking them and unblock if you decide to use them. |
| WebZIP |
Offline browser and web site downloader. URL: N/A (couldn't find an official link) Robots.txt Info: N/A (couldn't find an official link)
Note: High likelihood you want to block as we haven't seen any positive information about this bot online. |
| Xenu |
Link checker for broken links (used by many web design and SEO professionals). URL: https://home.snafu.de/tilman/xenulink.html Robots.txt Info: N/A (couldn't find an official link)
Note: If you're not using their tool, you may want to consider blocking them and unblock if you decide to use them. |
| CCBot |
Web crawler for Common Crawl providing a copy of the internet to internet researchers, companies and individuals for the purpose of research and analysis. URL: https://commoncrawl.org/ Robots.txt Info: https://commoncrawl.org/big-picture/frequently-asked-questions/
Note: Uncertain about this. Although we have not seen much positive information about them, the website and information seems legit. Please do your own research and share your opinion on this one. |
| CherryPicker |
Data extraction tool. URL: N/A (couldn't find an official link) Robots.txt Info: N/A (couldn't find an official link)
Note: High likelihood you want to block as we haven't seen any positive information about this bot online. |
| grub |
General purpose web crawler. URL: https://www.gnu.org/software/grub/index.html Robots.txt Info: N/A (couldn't find an official link)
Note: High likelihood you want to block as we haven't seen any positive information about this bot online. |
| libwww |
Programmatic way for developers to get webpages and content via code. URL: https://www.w3.org/Library/ Robots.txt Info: N/A (couldn't find an official link)
Note: Monitor your server logs and if you see traffic from it, you might want to block it assuming your developers are not using it. |
| Microsoft URL Control |
URL scanning and downloading. URL: N/A (couldn't find an official link) Robots.txt Info: N/A (couldn't find an official link)
Note: High likelihood you want to block as we haven't seen any positive information about this bot online. |
| Zeus |
Web robot. No much specified about them online. URL: N/A (couldn't find an official link) Robots.txt Info: N/A (couldn't find an official link)
Note: High likelihood you want to block as we haven't seen any positive information about this bot online. |
| AhrefsBot |
Web crawler for Ahrefs SEO tool. URL: https://ahrefs.com/ Robots.txt Info: https://ahrefs.com/robot
Note: If you're not using their tool, you may want to consider blocking them and unblock if you decide to use them. |
What Else We Found
- Content Creators Blocks: Many content creators such as media and news sites blocked ChatGPT from reading and using their data in their AI. The data and content is their intellectual property and they spent money and resources on this property and don't want others to use their data.
- Misbehaving Bots: Some websites have noted in their robots.txt that certain bots don't follow robots.txt guidelines as specified. The bots fail to honor requests made in the robots.txt. Due to this erratic behavior, these bots are often blocked entirely to prevent potential harm or disruption. It's good for you to monitor bots on the server level as well.
- Crawl Delay: A great feature that many websites use in the robots.txt called "crawl delay". This allows websites to specify how frequently a bot should send requests, ensuring that the site's server isn't overwhelmed by too many requests in a short span of time.
- Shopify Site Blocks: Although they are not in the top sites we researched, we found out that all Shopify e-commerce sites (tens of thousands), all block the "nutch" bot as they probably have much spam from it. Shopify robots.txt also default crawl delay AhrefsBot, Mj12bot & Pinterest Bots.
- SEO Tools Blocking: If your website or marketing team does NOT use these SEO tools, you may want to block them to have less load on your website. (examples include: semrush, rogerbot, dotbot, M12bot, xenu and ahrefsbot)
- Some Sites Block Almost All Bots: Some sites specify in their robots.txt to allow between 5-30 bots and block everything else. This is a great way to block a large amount of bots without specifying one by one. HOWEVER, be very careful if you follow this strategy to not block bots that you actually want. (high risk in this method if you make a mistake)
Common Q&A
- Q. Should i block ChatGPT from using my data? A. Depends. Some businesses think that users will not visit their site and go to ChatGPT to get the data therefore they want to block them or think that they're stealing their data. For One Scales, we want our information to spread so we are happy that more sources use our information.
- Q. Should i use "crawl-delay"? A. In many cases yes. If your servers cannot handle large amounts of traffic, you should consider crawl-delay for certain bots. You can ask your developer to check your logs and server compute power to see if bots are slowing down your website. Note that shopify and many others have certain bot crawl delays in place.
- Q. How do i learn more about robots.txt? A. In future we will make articles and videos about it but for time being we suggest to read more at https://developers.google.com/search/docs/crawling-indexing/robots/intro
- Q. What's the downside of blocking a bot? A. If you block a bot that is needed, you will not gain that functionality. For example - if you block google bot, then no one would be able to find your website on google.
- Q. How do i find out if a bot is good or bad? A. Ask your developer to check server access logs to see what these bots are doing on your site., secondly, google them - if you can't find an official guidelines from that company with robots.txt instructions on how to remove them, then high likelihood that its a bad bot and you want to consider removing them. Lastly, ask in the comments and participate in our community - we're here to help!
- Q. How do i find new bots that i didn't block that are causing issues on my site or stealing my data and information? A. Ask your developer to provide access logs and a list of bots. B. Follow our guide to doing it yourself via GTM and Google Sheets
Research Notes
- Good Bots vs. Bad Bots: It's important to remember that only the "good bots" respect and follow the directives in robots.txt. For this reason, relying solely on robots.txt for blocking might not be enough. You might want to consider server-level or firewall blocks to ward off more persistent or malicious bots.
- Counting of Total Number of Bots: Some bots have multiple versions, bots and names. In the counting, we combined the same bots into a single bot.
- Fully Blocked Bots: Our research focused solely on bots that are fully blocked, not those that are partially blocked. The reason we focused on fully blocked bots was because each site and business has different requirements and different pages and sections on the site that they want to block. Looking into partial blocks would give very little insight with a huge amount of manual labor to link into it.
- English Sites: The far majority of websites (231 out of 250) researched are in English. They were easy for us to categorize, review and understand. We included 19 non english sites in order to sample a few additional sites.
- List of Websites: reviewed from Similarweb top sites - https://www.similarweb.com/top-websites/.
- Categories of Top Websites Researched:
-
- Bank/Financial - 13 Websites
- Commerce/Products/Services - 48 Websites
- Government - 8 Websites
- Informational Sites (Media, Forums, Ads) - 92 Websites
- Informational Sites (News) - 19 Websites
- Search Engine - 7 Websites
- Social Media - 18 Websites
- Software & Saas - 35 Websites
- Travel - 10 Websites
- Always Do Your Own Research: Every site, business and situation is different. Do you own research, study well and think carefully before blocking bots.
The Full Website Research Data
Below is the link to view the full data. The sheet includes 2 tabs:
- "Raw Data" Tab - List of websites including categories and bots fully blocked.
Columns & Data:
- Column A - Website - Domain with robots.txt url.
- Column B - Website Category - The type of website.
- Column C - English Site - Is the website in English or not?
- Column D - Blocked Bots - If a bot is fully blocked, the name will be listed one by one in columns D to EI.
- "Count" Tab - includes the numbers of times a specific bot was blocked. Note they are grouped together if bot has multiple versions and names.
Columns & Data:
- Column A - Bot Name - The bot name listed on robots.txt.
- Column B - Block Count - How many websites blocked it.
Your Insights
We would love to hear from you your insights and experiences. Let us know in the comments below.
